During February, Someone contacted me on Linkedin and asked for some consultation in their RAG pipeline. Their fancy new ColBERT search system—the one that crushed benchmarks in testing—was melting their servers. Query latency jumped from 50ms to 5 seconds. “But the accuracy is so much better!” they kept saying, like a mantra, while customers fled to competitors. I suggested possible solutions and things got resolved in a balanced way.
That moment triggered my curiosity in this problem. Various companies have RAG implemented but they all struggle with a problem of fast and efficient retrieval.
In this article, we’ll discuss something nobody tells you about multi-vector search: it’s simultaneously the best and worst thing to happen to information retrieval. Recently Google just figured out how to fix it. We’ll explore their approach as well.
How we got here
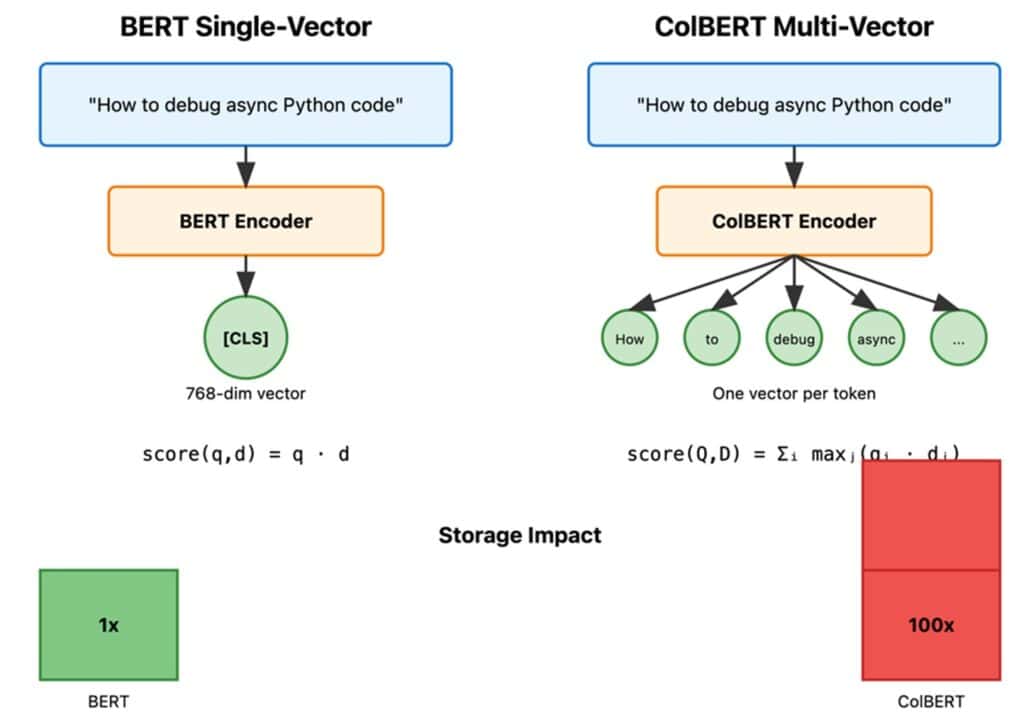
Remember when BERT first dropped? We all got drunk on the idea of shoving entire documents into a single vector. Take your text, feed it through BERT, grab the [CLS] token, and boom—you’ve got a dense representation.
Simple
Fast
Wrong
What’s wild is how badly this approach fails once you understand what’s happening. You’re taking War and Peace and saying “this book is about… uh… Russia?” It’s like describing the Mona Lisa as “a painting with a person.”
The math behind BERT’s similarity is deceptively simple:
score(q, d) = q · d = Σᵢ qᵢdᵢ
Just a dot product. Fast, but lossy as hell.
The problems hit you in production:
- User searches for “python async debugging tips”
- BERT vector matches documents about snakes, programming languages, and British comedy troupes equally well
- The actual debugging tips? Buried on page 3
- Your boss asks why the search sucks
So along comes ColBERT with a radical idea: keep ALL the token embeddings. Every. Single. One. Instead of one vector per document, you get hundreds. The similarity function becomes:
score(Q, D) = Σᵢ₌₁ⁿ maxⱼ₌₁ᵐ (qᵢ · dⱼ)
Where Q has n query tokens and D has m document tokens. It’s beautiful. It’s accurate.
It’s also computational suicide.
The dirty secret of multi-vector search
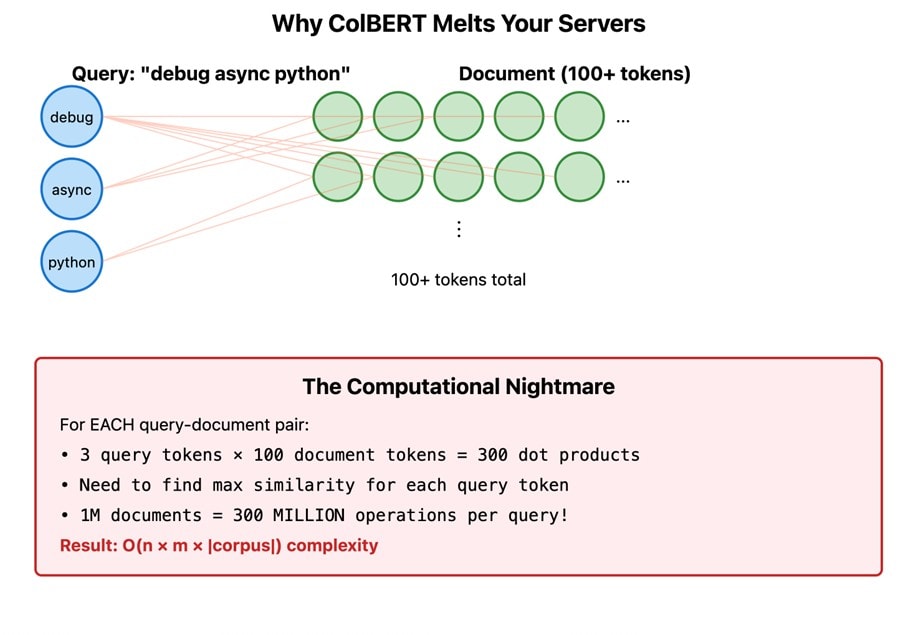
Here’s what the AI influencers don’t emphasize: ColBERT-style models are absolute monsters in production. The maths don’t lie. Single-vector search uses dot products—your CPU can do billions per second. Multi-vector search uses MaxSim scoring: for each query token, find its maximum similarity across all document tokens, then sum everything up. That’s not a dot product; that’s a matrix operation. For every. Single. Document.
The storage explodes. A million documents with BERT? That’s maybe 4GB of vectors. With ColBERT? Try 400GB. Hope you’ve got deep pockets for memory.
That’s where You lose all the speed tricks.
Those fancy approximate nearest neighbour algorithms that make vector search fast? They assume you’re comparing single points. Multi-vector similarity is non-linear. You’re back to brute force, like it’s 1999.
The “solutions” are embarrassing. PLAID tried to fix this by clustering tokens and building inverted indices. Still 10x slower than single-vector. Others use a two-stage approach: filter with BERT, re-rank with ColBERT. Except the documents ColBERT excels at finding are precisely the ones BERT filters out. Oops.
Google offered us MUVERA
June 2025, Google dropped MUVERA, and it’s one of those ideas that makes you angry you didn’t think of it first.
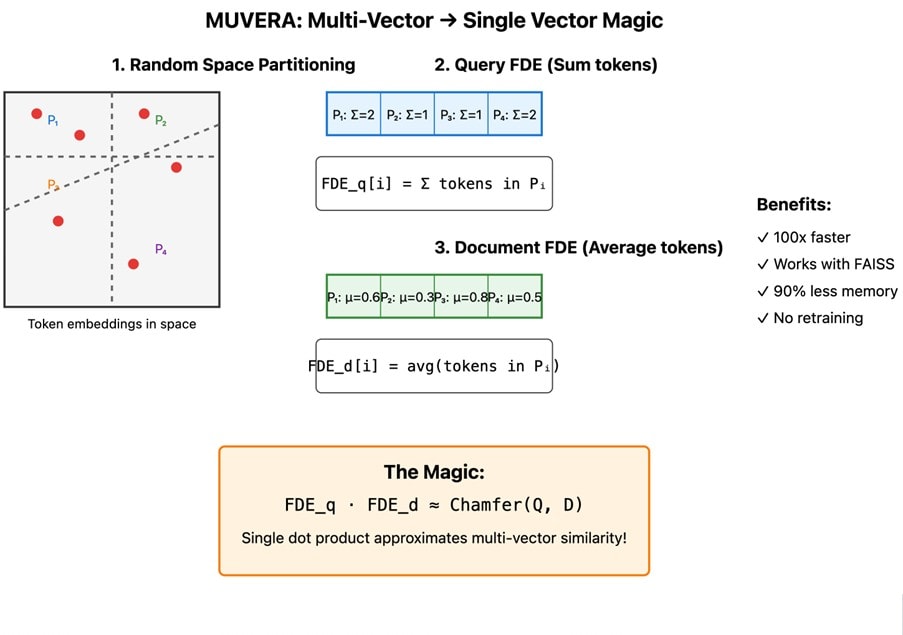
The insight is stupid simple: what if we could transform multi-vector sets into single vectors that preserve similarity relationships?
Not by averaging (that’s what we initially do), but through a principled mathematical transformation.
Here’s the trick:
- Take your high-dimensional space and randomly chop it up with hyperplanes
- For each chunk of space, allocate some dimensions in your output vector
- For documents: average the tokens that fall in each chunk
- For queries: sum the tokens in each chunk
- The inner product of these “Fixed Dimensional Encodings” approximates the original multi-vector similarity
The mathematical foundation is elegant. Given a partition function π that maps vectors to partition indices:
FDE_q[i] = Σ_{v∈Q, π(v)=i} v
FDE_d[i] = (1/|{v∈D : π(v)=i}|) × Σ_{v∈D, π(v)=i} v
And magically:
⟨FDE_q, FDE_d⟩ ≈ Chamfer(Q, D)
What makes this genius is what it DOESN’T do. It doesn’t require training. Doesn’t need to see your data. Doesn’t care if you’re searching emails or academic papers. It just… works.
Real numbers from real systems
Let me break down what MUVERA actually delivers, because the paper undersells how game-changing this is:
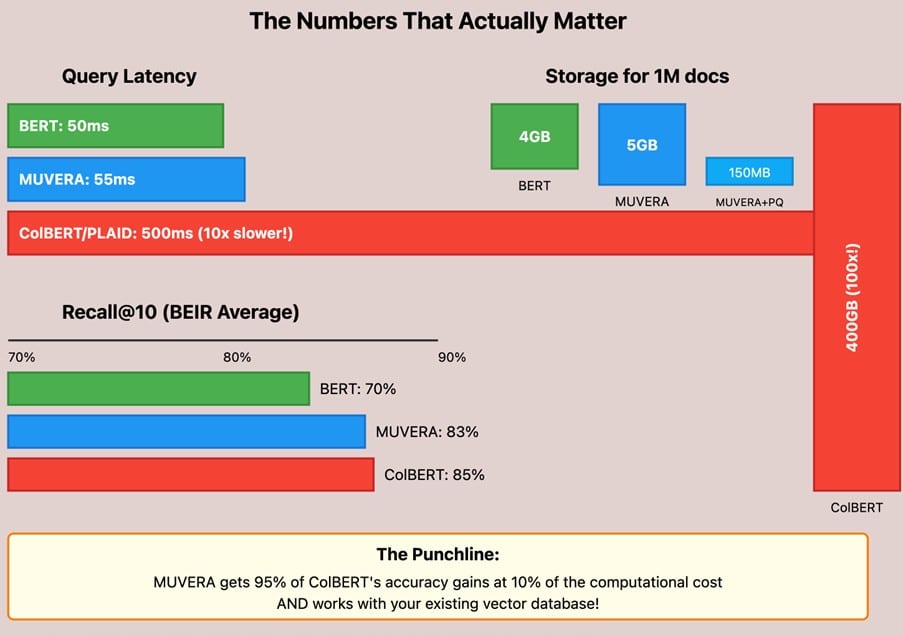
Traditional BERT setup
• 50ms average query latency
• 70% recall@10 on BEIR benchmarks
• 4GB index for 1M docs
• Works with any vector database
ColBERT (with PLAID optimizations):
• 500ms average latency (on a good day)
• 85% recall@10
• 400GB index
• Requires custom infrastructure
MUVERA
• 55ms average latency
• 83% recall@10
• 5GB index (or 150MB with compression!)
• Works with standard MIPS systems
The punchline? MUVERA is getting 95% of ColBERT’s accuracy gains at 10% of the computational cost. It’s not magic—it’s just good math.
Why this changes everything (and what it means for you)
What gets me excited is the meta-lesson here. We’ve been thinking about this problem wrong. Instead of building increasingly complex infrastructure for new model architectures, maybe we should be building better bridges between new models and existing systems.
The theoretical guarantee is what seals the deal. MUVERA proves that:
|⟨FDE_q, FDE_d⟩ – Chamfer(Q, D)| ≤ ε × Chamfer(Q, D)
With high probability for appropriate FDE dimensions. This isn’t hand-waving—it’s a provable approximation bound.
The alternatives people are chasing—custom silicon for matrix operations, learned indices, hybrid CPU/GPU systems—they’re all solving the wrong problem. MUVERA proves you can have your cake and eat it too, without reinventing the entire kitchen.
(Yes, there are edge cases where you need full ColBERT accuracy. If you’re Google Search, you probably run the full model. For the other 99.9% of us trying to build decent search? MUVERA can help.)
The future isn’t about choosing between simple-but-inaccurate or complex-but-slow. It’s about clever transformations that give us the best of both worlds. Sometimes the best engineering isn’t about building new systems—it’s about making existing systems do things they were never designed for.
References & bibliography:
- MUVERA Paper
- Title: “MUVERA: Multi-Vector Retrieval via Fixed Dimensional Encodings”
- Link: https://arxiv.org/abs/2405.19504
- Authors: Mentioned as work by Majid Hadian, Jason Lee, and Vahab Mirrokni
- ColBERT
- Title: ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT
- Link mentioned: https://arxiv.org/abs/2004.12832
- PLAID
- Paper: https://arxiv.org/pdf/2205.09707
- Described as ColBERT’s optimization attempt using clustering and inverted indices
- BEIR Benchmarks
- Paper: https://arxiv.org/abs/2104.08663
- Used for evaluating information retrieval performance
- Probabilistic Tree Embeddings
- Paper: https://arxiv.org/abs/2111.03528
- Mentioned as theoretical foundation for MUVERA’s approach
Technical concepts referenced
- BERT – For single-vector retrieval using [CLS] token embeddings
- MaxSim (Maximum Similarity) – The scoring function used in ColBERT
- Chamfer Similarity – The multi-vector similarity measure
- MIPS (Maximum Inner Product Search) – The optimization technique for vector search
- Product Quantization – For compressing FDEs
Tools/systems mentioned:
- FAISS, ScaNN – Vector database systems
- Pinecone, Weaviate, Qdrant – Commercial vector databases
- MS MARCO – Dataset where ColBERT shows 50-70% improvement
Other resources:
- GitHub Implementation
- MUVERA’s open-source implementation: https://github.com/google/graph-mining/tree/main/sketching/point_cloud
- Wikipedia Links (from the fetched content):
- Information retrieval: https://en.wikipedia.org/wiki/Information_retrieval
- Inner product space: https://en.wikipedia.org/wiki/Inner_product_space#Euclidean_vector_space
- Maximum inner product search: https://en.wikipedia.org/wiki/Maximum_inner-product_search
- Dot product: https://en.wikipedia.org/wiki/Dot_product
- Space partitioning: https://en.wikipedia.org/wiki/Space_partitioning
Do you have any AI related challenges? We would love to hear from you.
Let’s connect over a cup of coffee. Please email us at p.koning@devon.nl




No comment yet, add your voice below!